Дубли торговых точек и как с ними бороться
Петр работает аналитиком в федеральной компании, которая производит продукты и напитки.
Задача Петра — анализировать продажи и докладывать руководству, сколько денег заработала компания. Петру со школы нравятся цифры и графики, но иногда работа выводит его из себя.
Например, составлять отчеты о торговых точках — работа для сильных духом. В базе торговых точек полно дублей, из-за дублей невозможно посчитать реальные продажи, размер клиентской базы, эффективность торговых представителей.
В базе плодятся дубли, потому что не существует общепринятых надежных способов идентифицировать торговую точку.
Человек поймет, что «Тысяча мелочей» и «Магазин у дома „Тысяча мелочей“ НЕТ ДОГОВОРА» в базе данных — это одна и та же торговая точка. Хотя названия сильно отличаются.
При этом «Аптека № 5» и «Аптека № 6» — разные торговые точки, хоть названия очень похожи.
А вот научить этому условный Excel сложно.
Поскольку однозначного идентификатора нет, отличить одну точку от другой бывает сложно. Так в базе и появляются дубли, которые портят статистику. А от статистики зависит планирование дистрибьюции, продаж и вообще вся аналитика производителя.
Вычищать дубли из базы руками — адский труд. Нужно понимать, что компания Петра продает товары через 250 тысяч магазинов. Можно нанимать операторов, но они все равно ошибаются. Как находить дубли автоматически, непонятно.
В минуты слабости Петр машет на все рукой и принимает, что дублей в базе нет (хоть и знает, что есть).
И Петр не единственный бедолага — о дублях торговых точек знает любой производитель и дистрибьютор товаров повседневного спроса. Поэтому мы задумались, как облегчать жизнь многочисленных аналитиков.
В базах торговых точек часто бардак
Производители товаров широкого потребления не работают с покупателями напрямую. Цепочка сбыта выглядит так: производитель → дистрибьютор → торговая точка → покупатель.
И дистрибьюторы, и производители анализируют продажи в разрезе торговых точек:
- оценивают размер клиентской базы;
- прогнозируют спрос и продажи;
- проверяют эффективность работы торговых представителей.
Для точных отчетов нужно навести порядок в базе торговых точек. А там, как мы уже знаем, полно дублей. Вот как они появляются:
- торговая точка меняет название, и в базе заводят новую запись. Старая, естественно, остается;
- несколько дистрибьюторов работают с одной торговой точкой по разным товарам, и для производителя она существует в разных экземплярах;
- производитель меняет дистрибьютора, и торговые точки задваиваются. Потому что новый дистрибьютор хранит их в базе иначе, чем старый;
- люди, которые ведут базу торговых точек, ошибаются и по-разному записывают названия.
Оператор под диктовку с телефона записывает в базу магазин «Боярин». Откуда ему знать, что следовало бы «БояринЪ».
Не «схлопнув» дубли, не посчитать статистику
Если не вычистить из базы торговых точек дубли, вместо аналитики и прогнозирования выйдет ерунда.
План продаж нереален. Невозможно составить прогноз, если неизвестно, сколько точек будут продавать товары.
Дистрибьюторы выгрузили торговые точки, производитель объединил их в базу, получилось 700 штук. Под это количество производитель верстает план продаж.
Отчетный период заканчивается, приходит аналитика и выясняется неприятное: продажи не соответствуют предположениям. Все гораздо хуже, чем ожидали.
Производитель разбирается и обнаруживает: из 700 точек, которые выгрузили дистрибьюторы, 200 — дубли. Реальных магазинов всего 500, а этого мало.
Знай производитель о дублях заранее, он:
- составит адекватный план продаж;
- сократит число торговых представителей, если для реальной клиентской базы их слишком много;
- расширит клиентскую базу, найдя новые торговые точки.
Эффективность торговых точек неизвестна. Дистрибьюторы не знают, сколько товара кому отгружать. В одних торговых точках полки пустые, другие постоянно возвращают просрочку.
С трейд-маркетинговыми акциями тоже неразбериха. Например, по условиям акции точка закупает столько-то товара и получает бонус. Некий магазин выполняет условия, получает профит и все как будто довольны. Но в базе о магазине вместо одной записи три. В итоге производитель выдает бонус в тройном размере.
Торговые представители неэффективны. Дело торгпредов — гонять между торговыми точками по точным маршрутам. Но когда в базе куча дублей, маршруты превращаются в вермишель.
Руководитель думает, что на маршруте торгпреда 50 торговых точек, этого достаточно. На самом деле уникальных точек не 50, а 30 и торгпред работает вполноги. По-хорошему ему нужно бы отсыпать точек на маршрут, и щедро.
Хитрые торгпреды не рассказывают о проблемах, потому что с дублями легче выполнять дневную норму посещений.
Как «схлопывать» дубли, неясно — у торговых точек нет надежного идентификатора
Как очистить базу от дублей, сходу непонятно. Непонятно даже, на какие параметры смотреть, чтобы сопоставить торговые точки.
Пока мы думали, как помочь Петру справиться с дублями, перебрали несколько вариантов идентификации.
ИНН. Едва ли не самый бесполезный параметр для нашей задачи.
У одного юрлица может быть десяток магазинов с разными названиями. Объединим их по совпадению ИНН — получим десяток ложных дублей.
Бывает и наоборот — магазин в течение даже одного года успевает сменить юрлицо или ИП. Не меняя при этом торгового названия.
По названию торговой точки также невозможно уверенно восстановить реквизиты юрлица — обычно и название, и адрес отличаются от указанных в ЕГРЮЛ.
Название. Полезно только как вспомогательный параметр, потому что названия в документах и базах данных все пишут по-разному.
Один и тот же магазин «БояринЪ» запишут как «Боярин», «Бояринъ», «Баярин», «Баяринъ», «Супермаркет Боярин», «Мини-маркет Баяринъ» и еще десятком способов.
Адрес. Ситуация та же, что с названием, только хуже. Хотя есть стандарты Почты России, адреса все равно пишут как удобно, а не как положено.
Возьмем одну-единственную деталь адреса — слово «бульвар». Люди пишут и «бул.», и «б.», и «б-р», и «бульвар». А ты сиди и думай, об одном адресе идет речь или о разных.
Или вот один и тот же адрес:
- 620026, Свердловская область, Екатеринбург, улица Луначарского, 210в;
- Екб, Луначарского 210в;
- 620026, Ебург, Луначарского — 210-в.
И мы даже не говорим о действительно сложных случаях с адресами (писали о них на «Хабре»).
Координаты. Сначала показалось, что это более или менее рабочий идентификатор. Но потом мы столкнулись с проблемами:
- если координат нет в базе, их все равно придется определять по адресу. Далеко не всегда это можно сделать уверенно, а по ненадежным характеристикам и сравнивать нет смысла;
- в пределах длинных домов координаты иногда отличаются так сильно, что адрес становится более надежным критерием.
Получается, что в среднем идентифицировать торговые точки по координатам не более надёжно, чем по адресам.
«Дадата» наводит порядок в базе данных
Перепробовав разное и поразмыслив, мы научили «Дадату» находить дубли торговых точек по паре «название + адрес».
Вооружившись «Дадатой», вот как Петр чистит базу данных перед отчетами и прочей аналитикой.
Выгружает в excel-файл новые магазины, которые появились в учетной системе производителя. В таблице три столбца: «ID», «Название» и «Адрес».
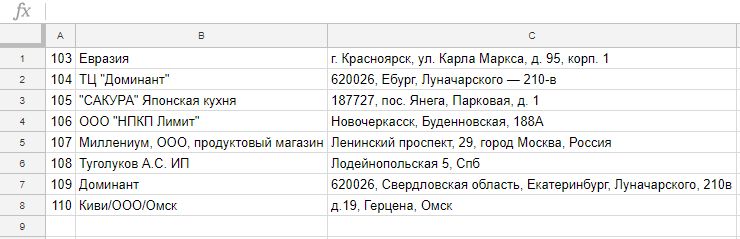
Если в базе торговых точек есть телефон — тоже пригодится
Загружает excel-файл в «Дадату», она отмечает одинаковые торговые точки. В таблицу с результатом проверки сервис вставляет два листа.
На первом одинаковые торговые точки сгруппированы и подсвечены.

«Дадата» не только находит дубли торговых точек, бонусом она приводит адреса к человеческому виду
В таблице остается исходный ID, а помимо него «Дадата» назначает каждой точке итоговый идентификатор. У дублированных точек он одинаковый, это и есть признак дублирования.
| ID в исх. файле | Итоговый ID |
|---|---|
| 104 | 2869 |
| 106 | 2864 |
| 109 | 2869 |
Исходный и итоговый идентификаторы пригодятся на следующих шагах.
На втором листе «Дадата» сразу объединяет одинаковые точки.
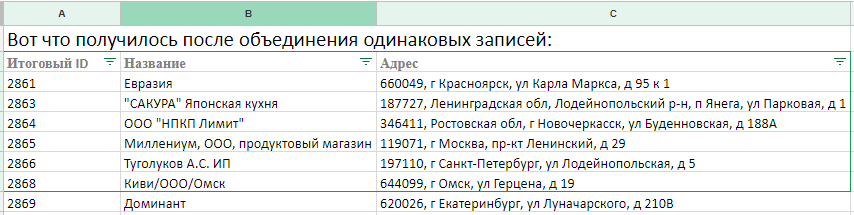
На этом листе сервис убирает исходные ID торговых точек. Дубли он здесь уже объединил, вспомогательных признаков дублирования не нужно
Можно сразу брать второй лист и не знать забот, но Петр не таков.
Петр страхуется и проверяет торговые точки, которые «Дадата» посчитала одинаковыми. (Потому что мало ли что там наобъединяли автоматически.)
Для проверки наш герой берет второй лист, где сервис сгруппировал точки, но не объединил. И смотрит, действительно ли там дубли или «Дадата» поспешила.
Загружает готовый excel-файл в учетную систему производителя. На этом шаге каждая конкретная система распорядится файлом по-своему в зависимости от настроек. Учетная система нашего производителя смотрит только на два поля: «ID в исх. файле» и «Итоговый ID».
Система рассуждает так: если итоговый ID у точек одинаковый, значит, нужно по исходным ID найти эти точки во внутренней базе и объединить.
В итоге учетная система «схлопывает» дубли, Петр доволен: отчеты будут чисты и прозрачны как хрусталь. Главное, каждые три месяца чистить базу (можно хоть каждый день, просто у нашего производителя принято раз в три месяца).
Подготовленного названия и адреса достаточно для нахождения дублей
Вы спросите: «Как же так? Сами пишете, что по названиям и адресам бесполезно идентифицировать, и сами же идентифицируете». Справедливо, сейчас объясню.
Дело в том, что «Дадата» смекалистая. Она очищает название от шелухи и оставляет только смысловую основу. И вот по ней можно искать дубли достаточно точно.
Когда «Дадата» очистит названия «Социальная Аптека 6 (104, г.Батайск)» и «Батайск, Социальная Аптека 6, д. 104» от них останется только смысловая часть: «Социальная Аптека 6».
(Подробно о том, как именно «Дадата» находит и сравнивает смысловые основы, мы писали на «Хабре».)
Адреса «Дадата» сравнивает тоже не с бухты-барахты. Сначала она приводит адреса к единому каноническому виду, и только потом смотрит, насколько те похожи.
«Ниж Нов» и «Н. Новгород» сервис переименует в «г. Нижний Новгород».
«ул. Эсперанто» в Казани «Дадата» обновит до «ул. Нурсултана Назарбаева», потому что улицу давно переименовали.
«б Рокоссовского» и «Бул. Рокосовского» расправят плечи и превратятся в «б-р Маршала Рокоссовского».
Похожесть адреса и похожесть названия сами по себе — не самые надежные критерии. Но в совокупности они дают достаточно уверенную оценку одинаковости торговых точек.
В чём «Дадата» не поможет
Есть ситуации, когда «Дадата» бессильна и вообще едва ли можно что-то сделать автоматически.
Учесть торговые точки с альтернативными названиями. Иногда один магазин фигурирует в документах под разными именами.
Название магазина «О’кей», кто-то запишет как «Okey», а кто-то вообще «OK» для краткости.
«Дадата» ищет дубли только по названиям, которое указали в загруженном excel-файле.
Объединить дубли сразу внутри учетной системы производителя. «Дадата» находит дубли в файле, который загружает пользователь. Потом кому-то придётся перенести результат в систему, из которой выгрузили торговые точки.
Хорошая новость — «Дадата» даёт достаточно данных, чтобы объединение не стало проблемой. Сервис назначает точкам-дублям одинаковый итоговый ID. Остается допилить учетную систему, чтобы она брала из excel-файла точки с одинаковыми ID и объединяла в своей базе. Это просто.
Избавиться от дублей в наименованиях товаров. С товарами проблема примерно такая же, как с торговыми точками — все пишут названия по-разному и не используют коды производителя. От этого образуются дубли, которые точно так же мешают аналитике.
«Дадата» здесь не поможет — она не ищет дубли в номенклатурных справочниках.
В остальном мы придумали простой и надежный способ убрать дубли торговых точек. И недорогой — «Дадата» чистит дубли по копейке за штуку.
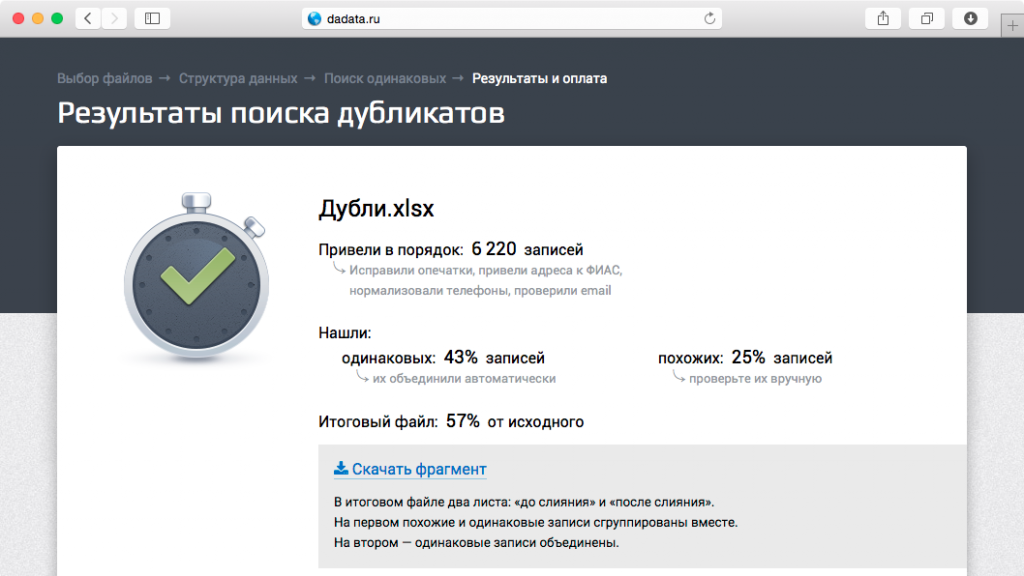
Можно загрузить базу, посмотреть, что нашла «Дадата», и только потом платить
Чтобы посмотреть, сколько дублей в вашей базе торговых точек, зарегистрируйтесь на dadata.ru. Загрузите excel-файл с базой, и сервис проверит ее бесплатно.
