Откуда приходят «кентавры», которые топчут клиентскую базу, и как их остановить
На Geektimes вышла статья разгневанного клиента «Альфастрахования»: он увидел в своем личном кабинете чужие полисы и персональные данные.

Три полиса принадлежат автору статьи, остальные — непонятно кому. (Скриншот из оригинальной статьи)
В комментариях увлеченно обсуждают причины утечки.
Дело якобы в неправильно выбранном ключе базы данных

Конечно, изобличают разработчиков в «этой стране»
В реальности ключи базы данных и разработчики не при чем: автор статьи наткнулся на типичного «кентавра». Так разработчики CDI-систем называют клиентские карточки, объединяющие данные разных людей.
Посмотрим, как эта проблема возникает и как ее решить.
Почему проблема не в базе данных
Если у офлайн-бизнеса с миллионами клиентов больше одного продукта, то клиентские данные гарантированно хранятся в разных IT-системах. У каждой своя степень заполненности, свой формат и качество данных.
Страховые ведут разные виды полисов в разных базах данных. Совместить в одной учетной системе ОСАГО и ДМС невозможно.
В банке кредиты и депозиты разносят в разные автоматизированные банковские системы (АБС). Кроме кредитов и депозитов у банка еще десятки продуктов.
В любой учетной системе, пусть компания хранит полисы или банковские счета, основной сущностью является продукт.
Оформляя при выезде за рубеж страховку, вы каждый раз создаете новую запись в учетной системе полисов ВЗР.
Никакой базы данных клиентов у крупного бизнеса попросту нет.
Что происходит, когда крупный бизнес становится клиентоориентированным
Представим, что огромная компания становится клиентоориентированной. При этом в центр IT-инфраструктуры ставят клиентов, а не продукты. Поэтому компания собирает данные, которые десятки лет копила в десятках разобщенных систем.
Мудрый бизнес не изобретает велосипед, а покупает профессиональное CDI-решение.
Чтобы условный Сергей Владимирович Иванов увидел все свои условные полисы в онлайн-кабинете, CDI-система делает следующее:
- Собирает клиентские данные из всех IT-систем компании.
- Приводит данные к стандартизированному виду.
- Находит дубликаты клиентских записей.
- Объединяет гарантированные дубликаты.
«Кентавры» зарождаются на шагах 3 и 4, с ними и будем разбираться.
Чтобы найти дубликаты, нужно понять, каких клиентов считать похожими.
- ФИО;
- дат и мест рождения;
- паспортных данных;
- адресов;
- контактных данных;
- связанных физических и юридических лиц;
- реквизитов договоров;
- и других.
Правила бывают простые: «ФИО, даты рождения и паспорт совпадают». Часто они намного сложнее: «ФИО похожи с вероятностью 70-80, хотя бы один адрес похож с вероятностью 90-100, даты рождения совпадают».
Набор правил зависит от специфики бизнеса, очень важно ее понимать. Например, свои «пакеты» условий мы собирали 12 лет и собираем до сих пор.
Часть правил «гарантированные» — найденные по ним дубликаты система объединяет автоматически.
«Негарантированные» дубликаты CDI-система отправляет на разбор дата-стюардам.
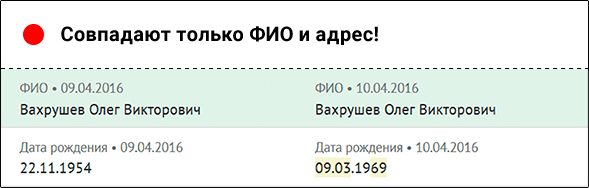
Если нужно, стюарды запросят копии или сканы документов и разберутся, относятся ли записи к одному человеку
Дубликаты, которые система не объединила и отправила дата-стюардам, называются «серой зоной». Чем больше «серая зона», тем меньше порядка. Из-за нее компания даже не может посчитать клиентов, не говоря о более сложных вещах.
Пусть у страховой компании «Ваше спокойствие» три IT-системы:
- полисы ДМС, 10 млн записей;
- ОСАГО и КАСКО, 20 млн записей;
- авиастраховки, 30 млн записей.
Может показаться, что у «Вашего спокойствия» 60 млн клиентов. Но мы знаем, что среди записей есть дубликаты.
Страховая внедрила CDI-систему. Наша статистика говорит, что в базе на 60 млн записей в среднем около 6 млн дубликатов. Для простоты будем считать, что все дубликаты парные.
Если половина из найденных пар гарантированные, в итоге получаем следующую базу:
- 54 млн одиночных карточек;
- 1,5 млн объединенных карточек;
- 3 млн. в «серой зоне».
В крайнем значении все пары из «серой зоны» — дубли. Тогда это 1,5 млн клиентов. Противоположная крайность — в серой зоне нет дублей, тогда это 3 млн разных клиентов.
Пока «серая зона» существует, правильным ответом на вопрос: «Сколько у страховой компании клиентов?» будет: «от 57 до 58,5 млн». Погрешность в 1,5 млн клиентов, точнее сказать нельзя.
В такой ситуации дата-стюарды помогут плохо. Внимательный разбор пары дубликатов занимает 15-30 минут. Разбор «серой зоны» в 3 млн клиентов потребует 2500 человеко-месяцев.
Сложнейшая задача при объединении дублей: подобрать порог «гарантированности» дублей. Он должен быть таким, чтобы все данные клиента слились в одну карточку, а однофамильцы и похожие личности остались снаружи. Здесь и появляется конфликт интересов.
В жизни CDI-проект — дело далеко не только техники. За внедрением и промышленной эксплуатацией IT-системы стоят люди. Они работают в разных отделах, у них разные задачи в компании, разные представления об идеальной картине мира. В конце концов, разные KPI.
Чисто техническая задача по внедрению и поддержке CDI-системы превращается в игру престолов и битву королей.
Из-за чего CDI-проект превращается в перетягивание каната
Первая задача CDI-системы — построить «золотую» базу клиентов. Но просто так от неё пользы мало, её нужно использовать. Бизнес-подразделения компании хотят это делать по-своему.
- Отделы аналитики и маркетинга хотят объединить как можно больше записей. Так профили клиентов насытятся данными, их проще будет делить на сегменты;
- отделу продаж поставили KPI на количество продуктов у одного клиента. Поэтому он тоже заинтересован в объединении;
- служба безопасности противится тому, чтобы слить клиентов с опечаткой в месте выдачи паспорта: как бы чего не вышло;
- отдел по работе с задолженностями требует как можно больше контактов должников. Конечно, он за снижение порога «гарантированности».
А еще данные включают в отчетность для регуляторов. Здесь ошибки вообще недопустимы, а порог «гарантированности» максимальный.
На решение влияет слишком много факторов, CDI-проект затягивается. Кажется, что правильного ответа нет.
Как правильно
Мы в HFLabs нашли, как решить проблему с порогом «гарантированности» и «кентаврами». Прежде всего нужно принять: никакого порога не существует.
Клиентские данные в любом бизнесе постоянно меняются: появляются новые продукты и процессы, подразделения и филиалы. Правила работы с дубликатами нужно менять вместе с ними. Не получится один раз все настроить и забыть.
Поэтому мы все время говорим с потребителями данных внутри компании-заказчика, выясняем потребности. Анализируем данные, изменения в них. Ищем закономерности и проверяем гипотезы на тысячах тестов. Если нашли ошибку, откатываемся на предыдущую версию и разъединяем объединенные карточки. А потом снова анализируем.
Чтобы поддерживать порядок в клиентских данных, нужно вкладываться каждый день. Иначе наступит хаос.
Другого рецепта качественной мастер-базы у нас нет.
